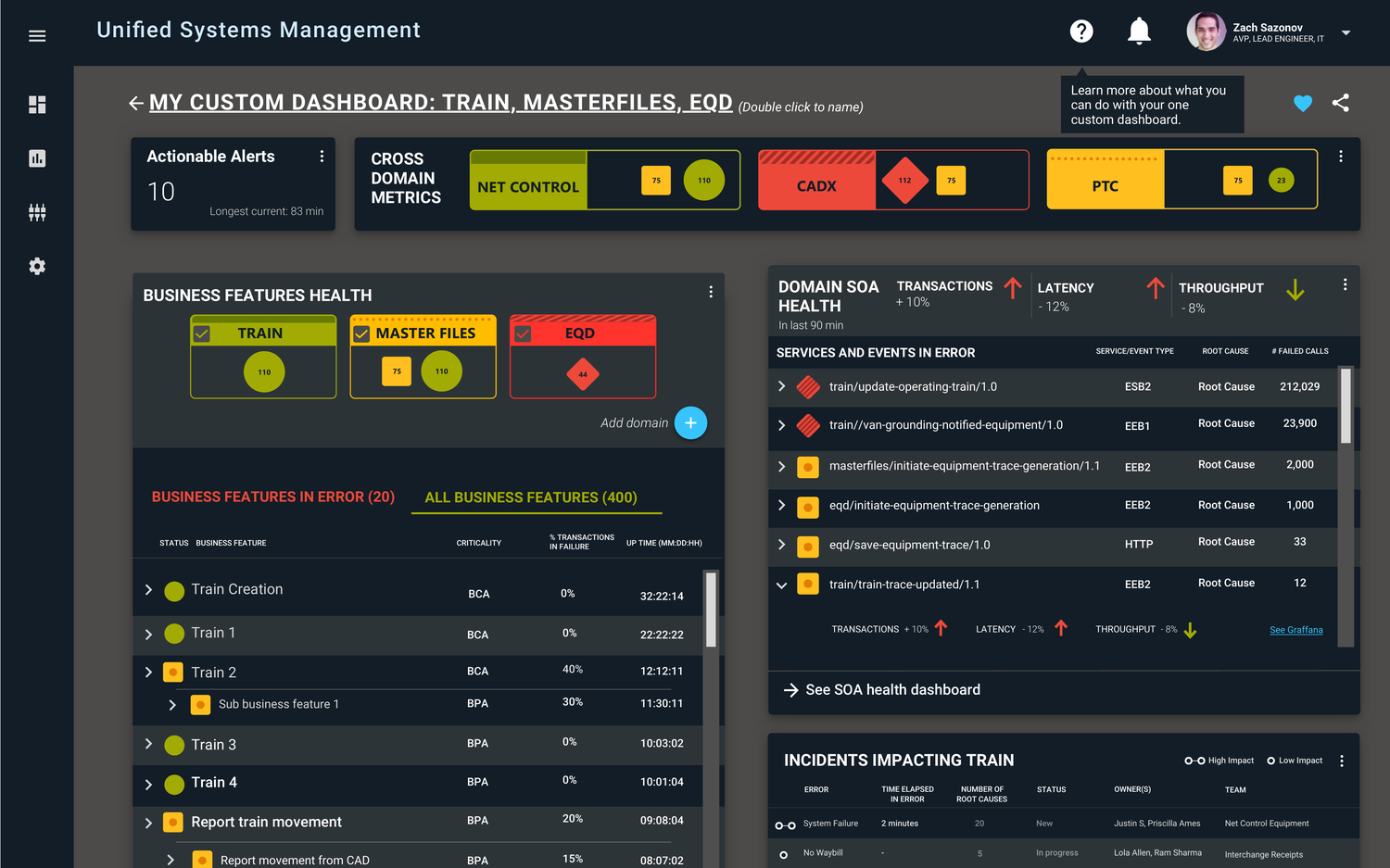
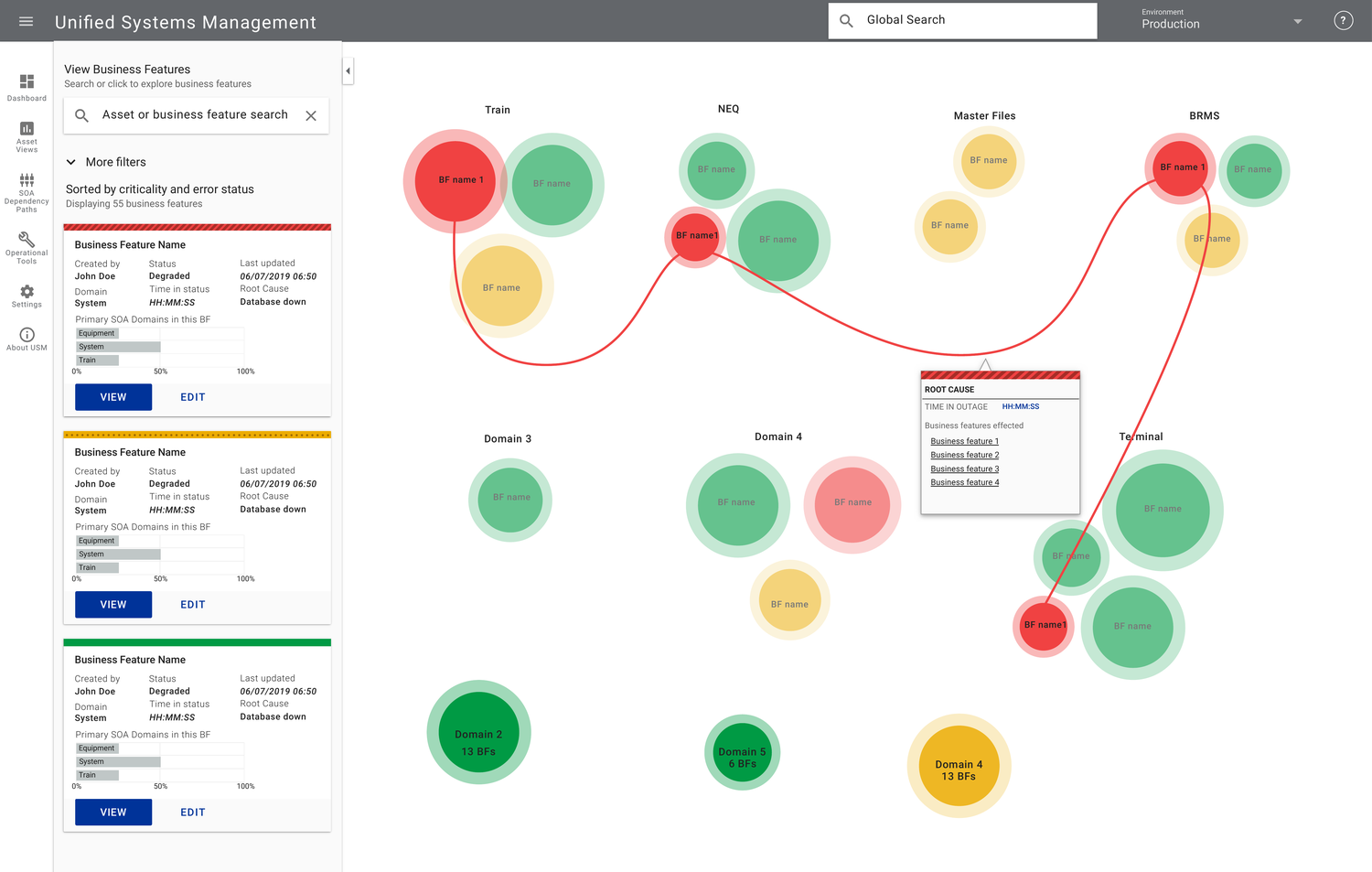
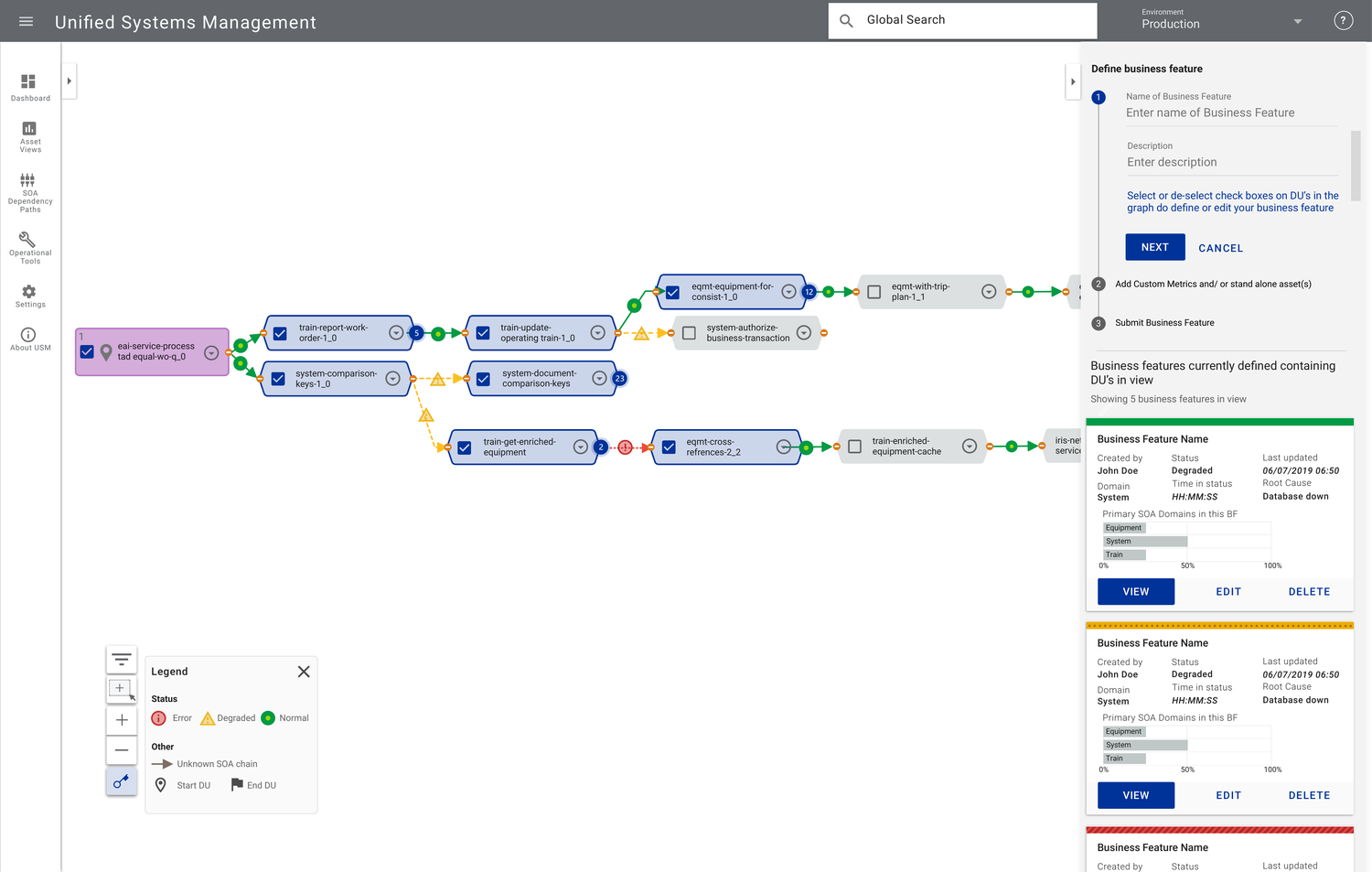
Overview
One view into the health of a railroad's entire IT infrastructure
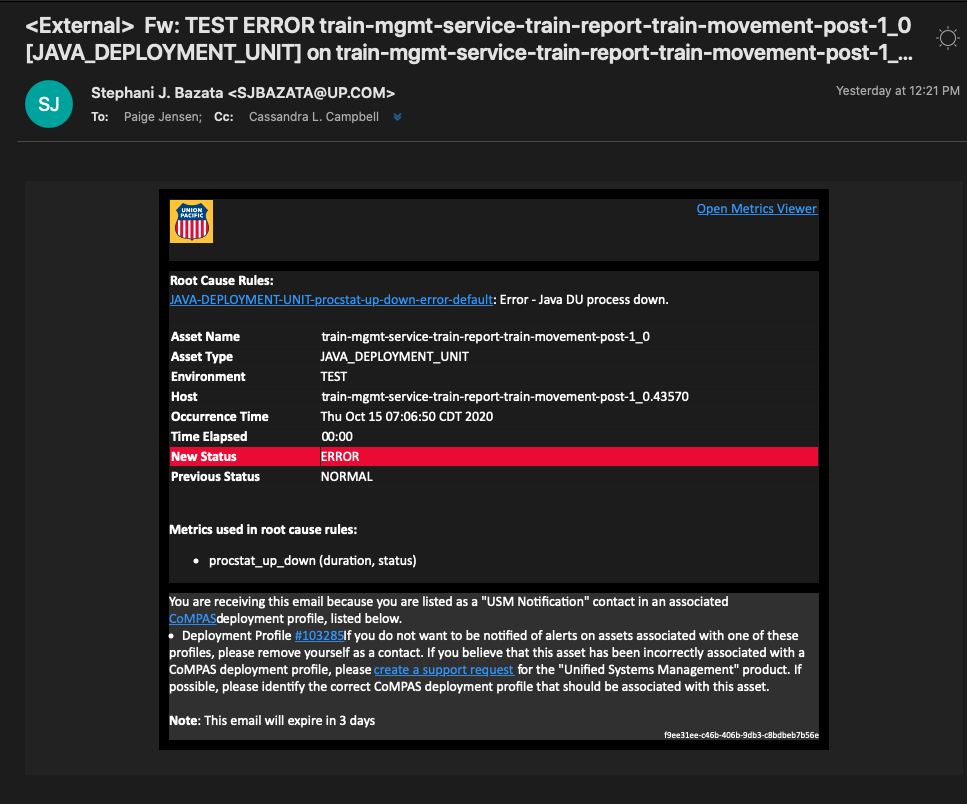
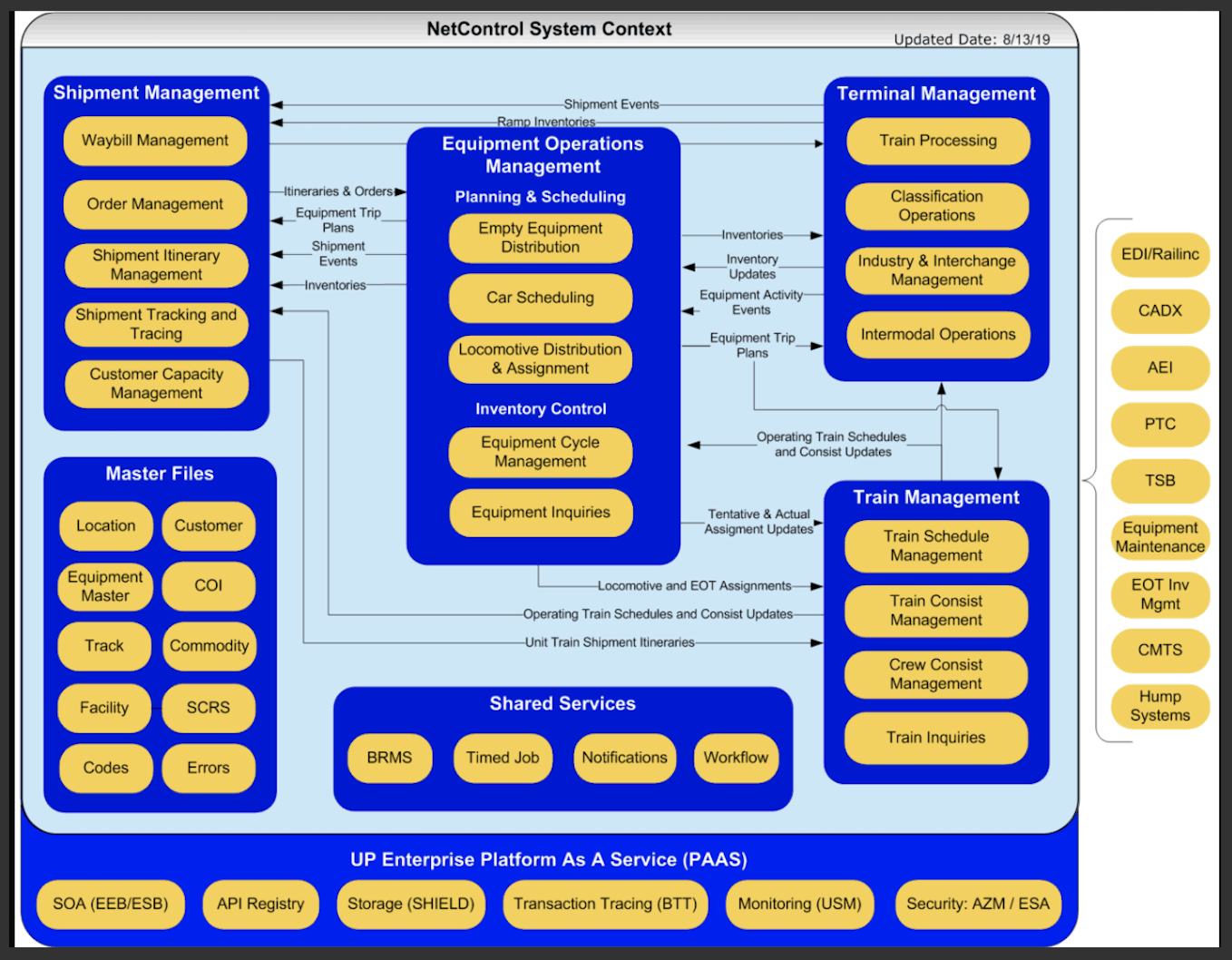
Unified Systems Management (USM) is an IT infrastructure-management platform for Union Pacific Railroad, one of America's largest freight railroads. Its job: surface the health of UPRR's sprawling systems in real time, alert the right team the moment something goes wrong, and get the right level of information to the right person so incidents get resolved fast.
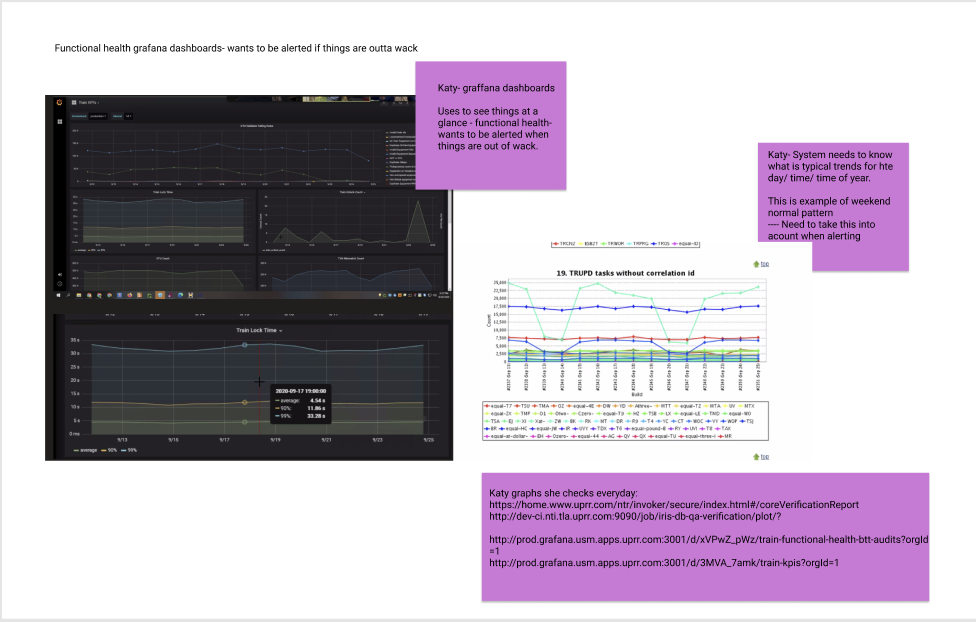
The goals were concrete: reduce mean time to detection and recovery (driving higher availability), mitigate risk with real-time access to critical information, route alerts to the right support team based on root cause, and give every role the right altitude of data — from a single executive health score down to an engineer tracing a failing service.
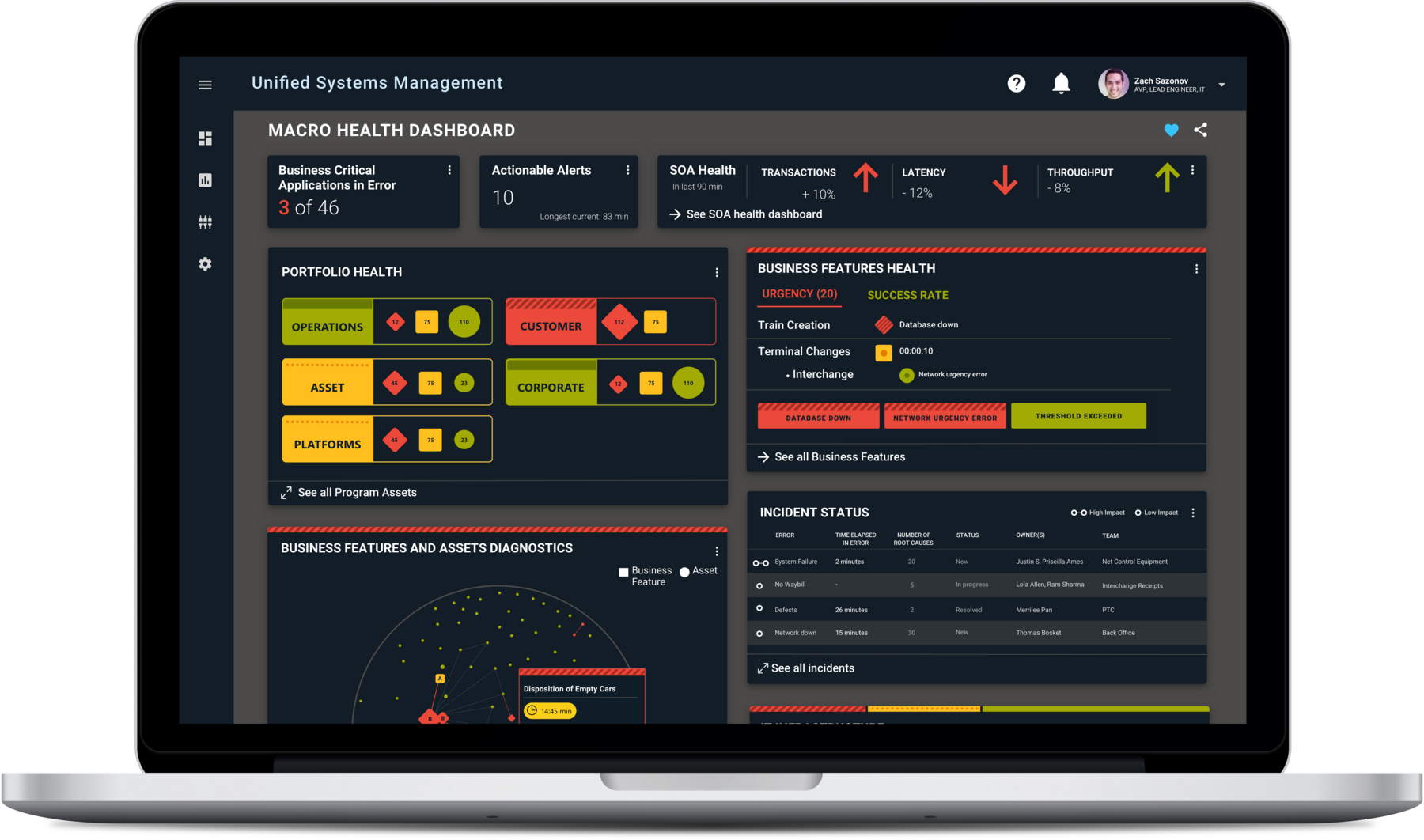
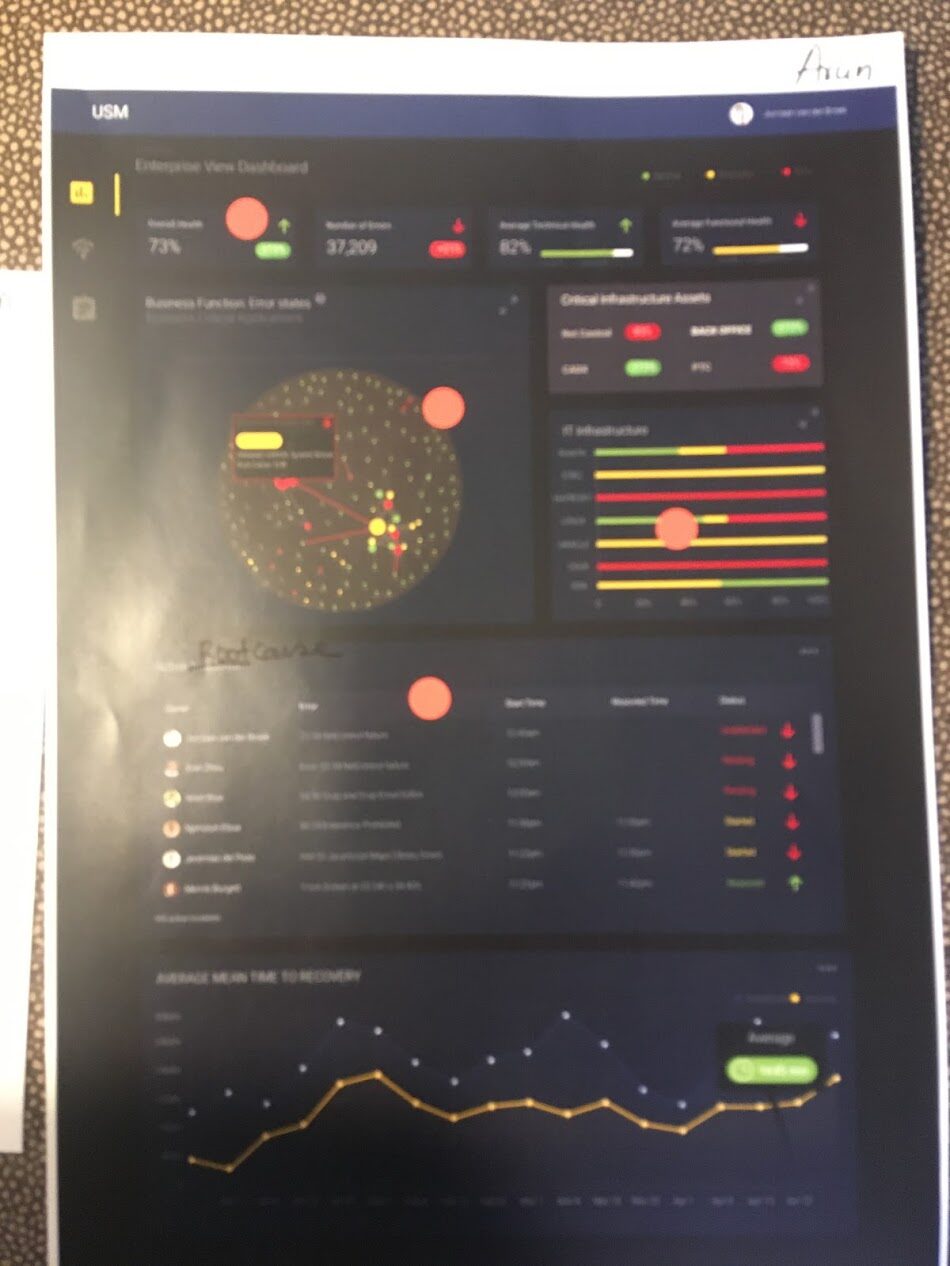
The USM Macro Health Dashboard — the entire enterprise's system health in a single, drill-downable view.